In this post I want to motivate the fundamental data structures that underlie Git. It will not be an in-depth treatment — just enough to have an intuition to know how Git can seemingly travel through time. I seemed to have used up my quota of technical jargon in the previous post so I’ll restraint myself here. (I promise not to use the term ”Merkle trees” anywhere!)
Maybe let’s start with the dumbest possible way you could implement something like Git. Imagine I have some directory whose contents I want to keep track of. Whenever I want to save a checkpoint of my work, I zip the entire directory and name the zip file as the current timestamp. Over time, I’ll end up with a bunch of zip files of the directory at different points in time.
That’s really what Git does. Everything else is an optimization of space, so that you don’t eventually run out of space on your computer after a while.
A directory can be represented as a tree. The root of the tree represents the directory which is being kept under version control, internal nodes represent subdirectories, and leaves represent files:
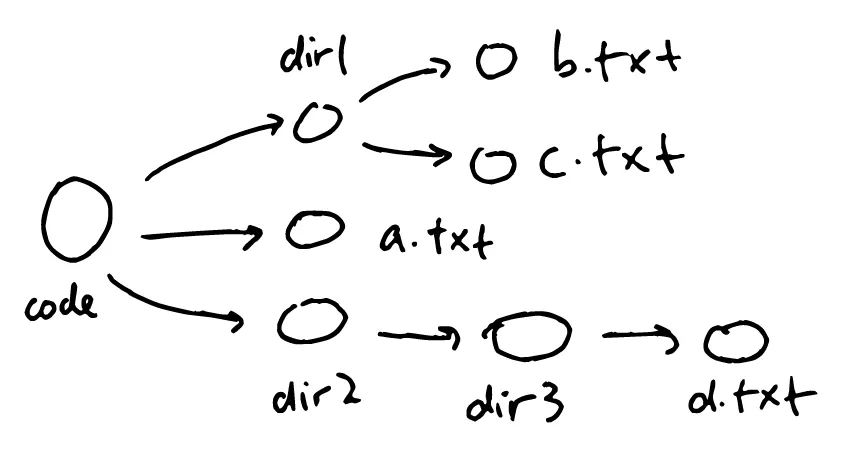
And me creating a zip file of the entire directory at different times looks like this:
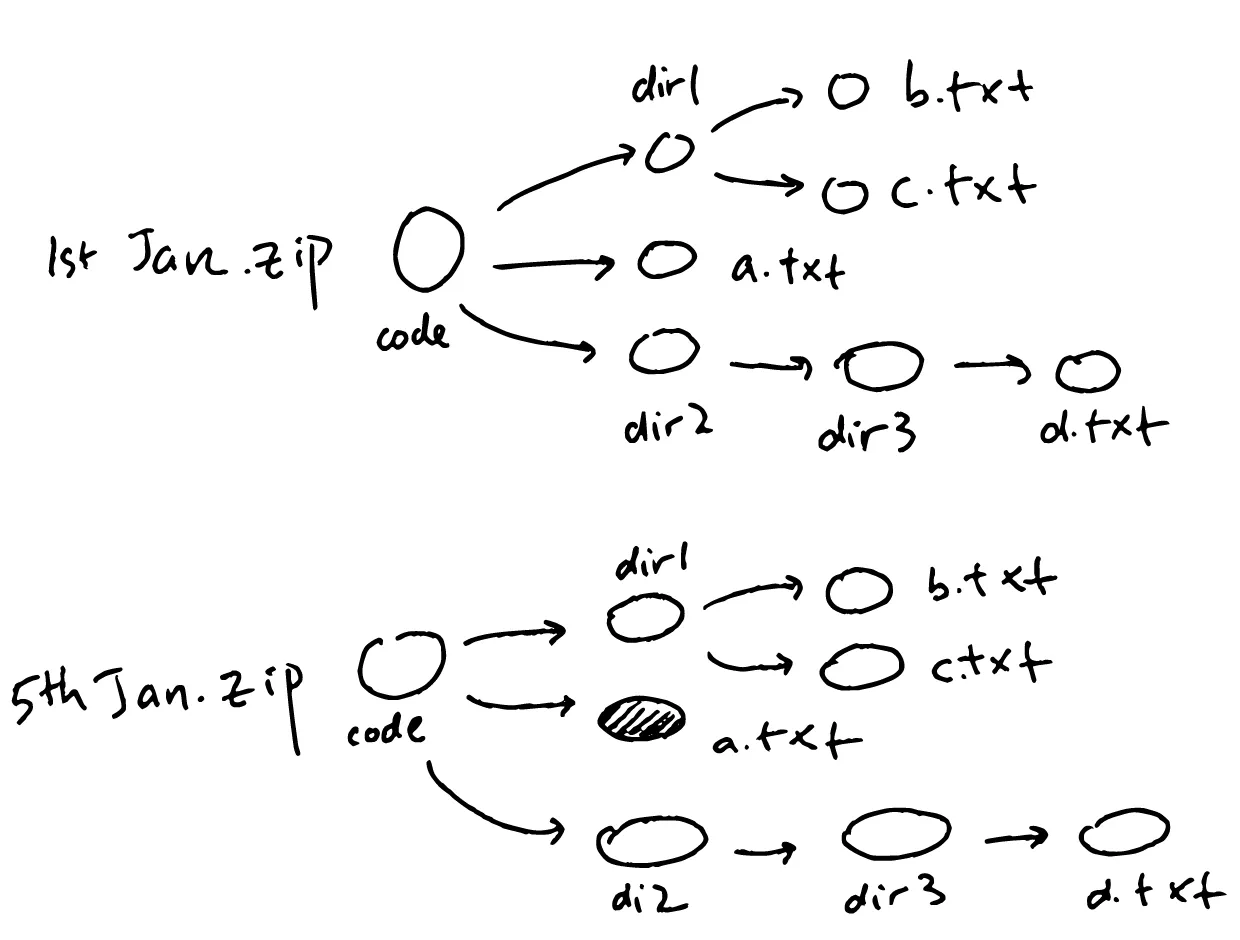
If I had a huge directory containing thousands of files, even if I’ve only changed one file, I’d still have a zip file that’s almost the same size as the previous one, since it contains a duplicate of all the other files that haven’t changed.
What if we could have a way to reference parts of the tree that didn’t change?
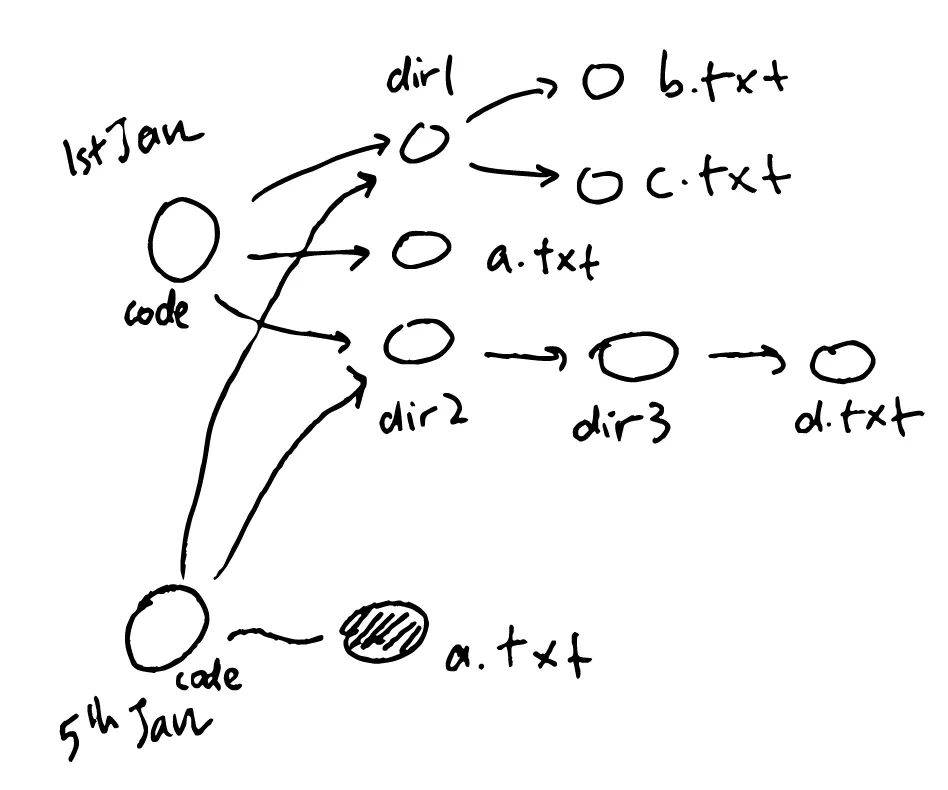
So the way Git does this is to basically have a way to track which parts of the tree has changed. It does this by using a hash function to hash files and subdirectories.
Let’s see how the hashing process works. Files are hashed one by one (here I’m using an imaginary hash function):
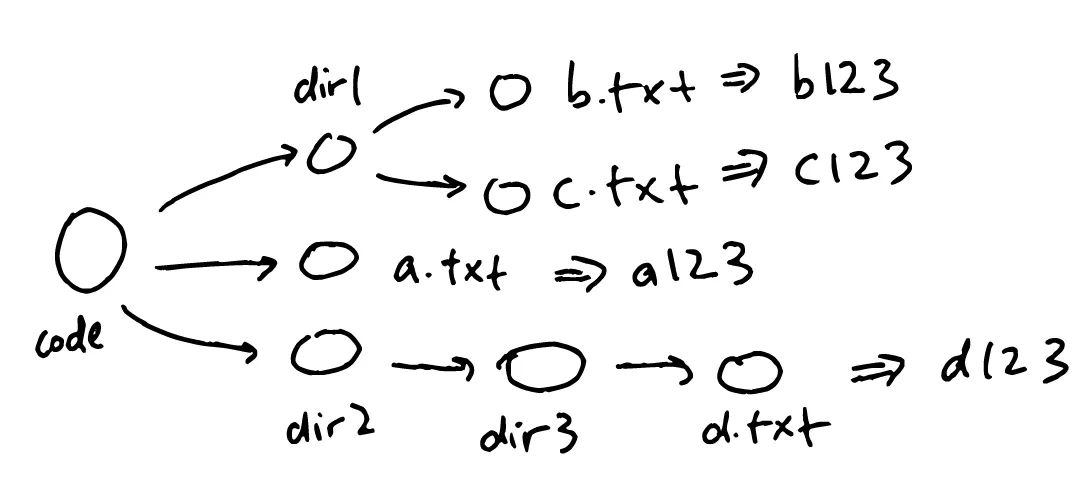
Subdirectories are only slightly trickier. The contents of a subdirectory is listed in a text file, with the name of each item and its hash on each line:
For dir1, it looks like this:
b.txt b123
c.txt c123and for the root directory code, it looks like this:
dir1 d1123
a.txt a123
dir2 d2123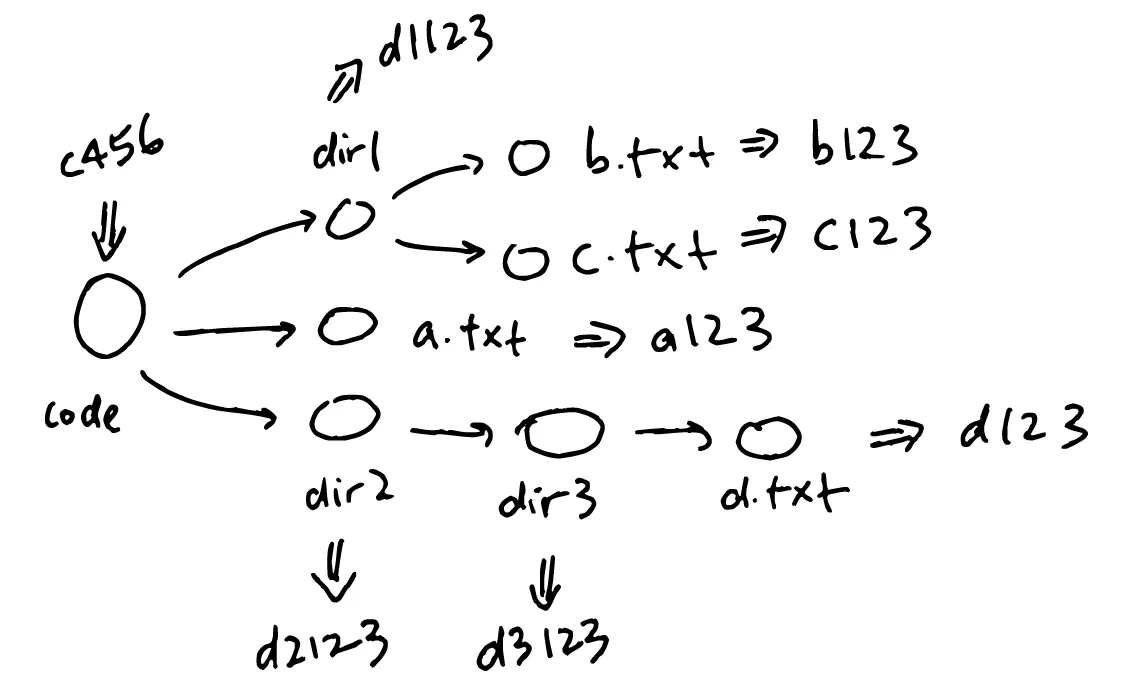
Notice that code has a mix of files and other subdirectories. That’s fine — each file and subdirectory will have its own hash. This text file is then itself hashed.
Now, recall that each file’s hash changes when the contents change, and each directory’s hash is based off the contents of the directory. So, it stands to reason that if anything in the directory changes (and this includes anything in the directory’s subdirectories), then the directory’s hash will change too.
Perhaps more importantly, the converse is true as well — if a directory’s hash is the same, then we can be sure that everything in the directory, including all its subdirectories, has not changed.
So, the way Git shares parts of the tree is by only creating new pieces of information for those parts of the tree that’s changed:
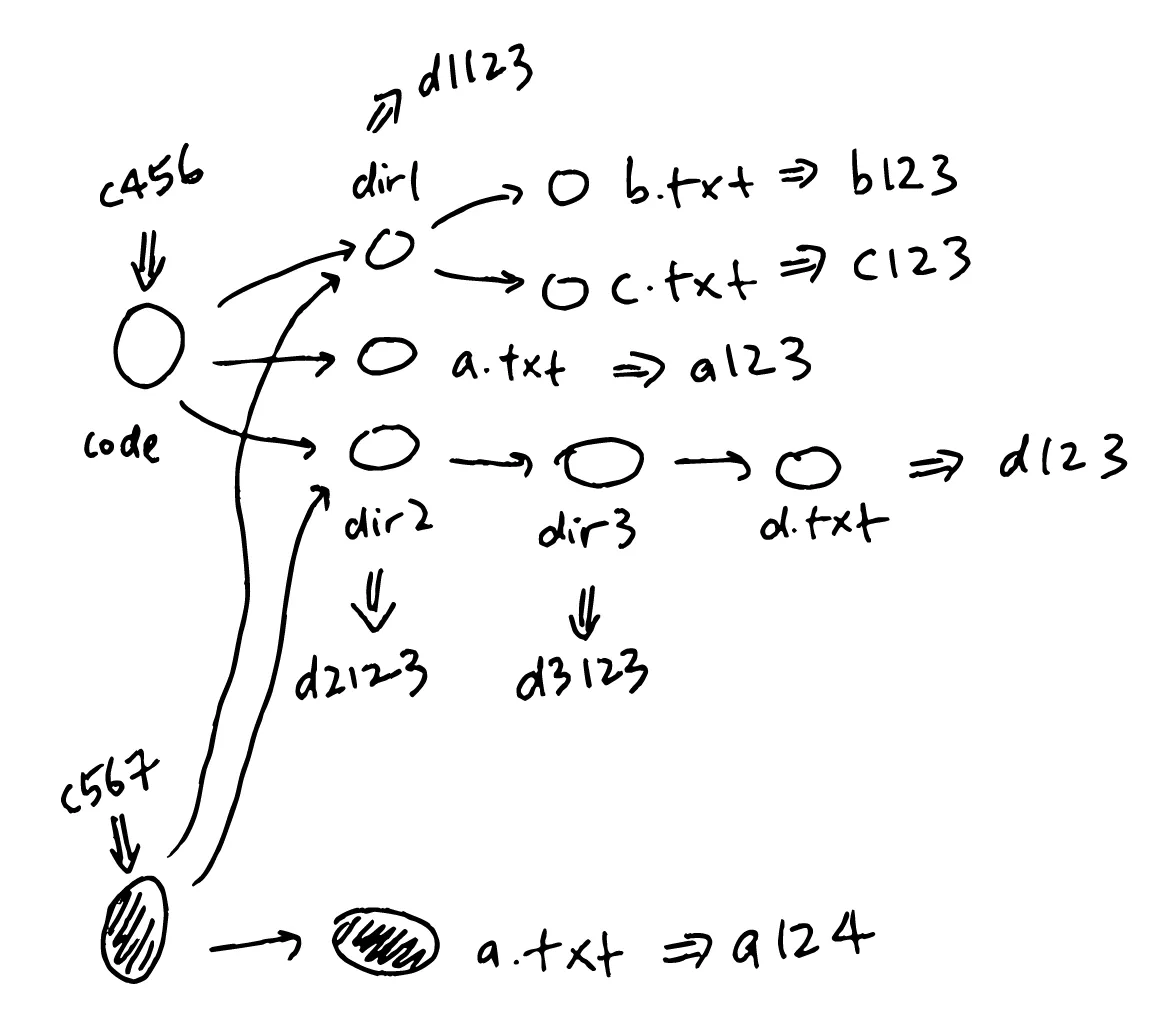
Recall that the text file that represented code looked like this:
dir1 d1123
a.txt a123
dir2 d2123After we modified a.txt, the hash of the modified file has been changed from a123 to a124, so the text file that represents code now looks like this:
dir1 d1123
a.txt a124
dir2 d2123Notice that dir1 and dir2’s hashes are the same, meaning that we can “reuse” them from the previous commit. That text file is then hashed, producing a different string c567.
Since we’ve covered trees and files, where do commits come into the picture?
Commits are just another piece of information that’s associated with each top-level tree object. Commits are what ties trees together and gives them continuity through time by storing its parent’s hash, besides also containing the commit message, commit author, and commit date:
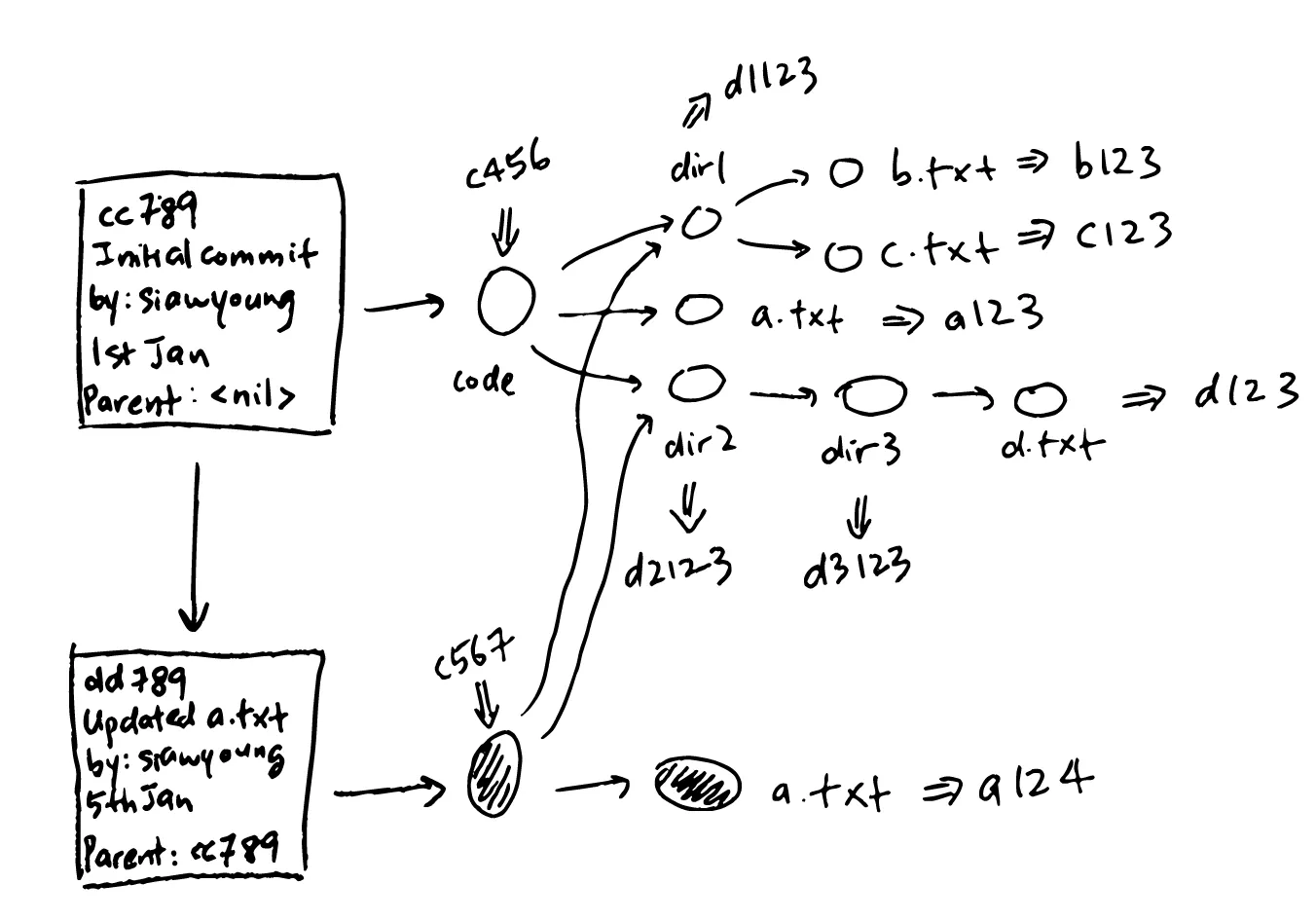
And that’s it!
Now that we know how Git works, let’s try something interesting.
Do this in your terminal:
mkdir -p test-git/dir1/dir2/dir3/dir4/dir5
cd test-git
git init
echo "Test" > dir1/dir2/dir3/dir4/dir5/a.txt
git add .
git commit -m "Initial commit"
du -sh .gitYou should see a directory size of 124K:
124K .gitCreate a few more commits:
echo "Test" >> dir1/dir2/dir3/dir4/dir5/a.txt
git commit -am "Second commit"
du -sh .git156K .gitecho "Test" >> dir1/dir2/dir3/dir4/dir5/a.txt
git commit -am "Third commit"
du -sh .git188K .gitNotice how the directoy size of .git seems to increase as a multiple of 32K every commit even though we’ve only changed 1 file? Here’s why it’s happening:
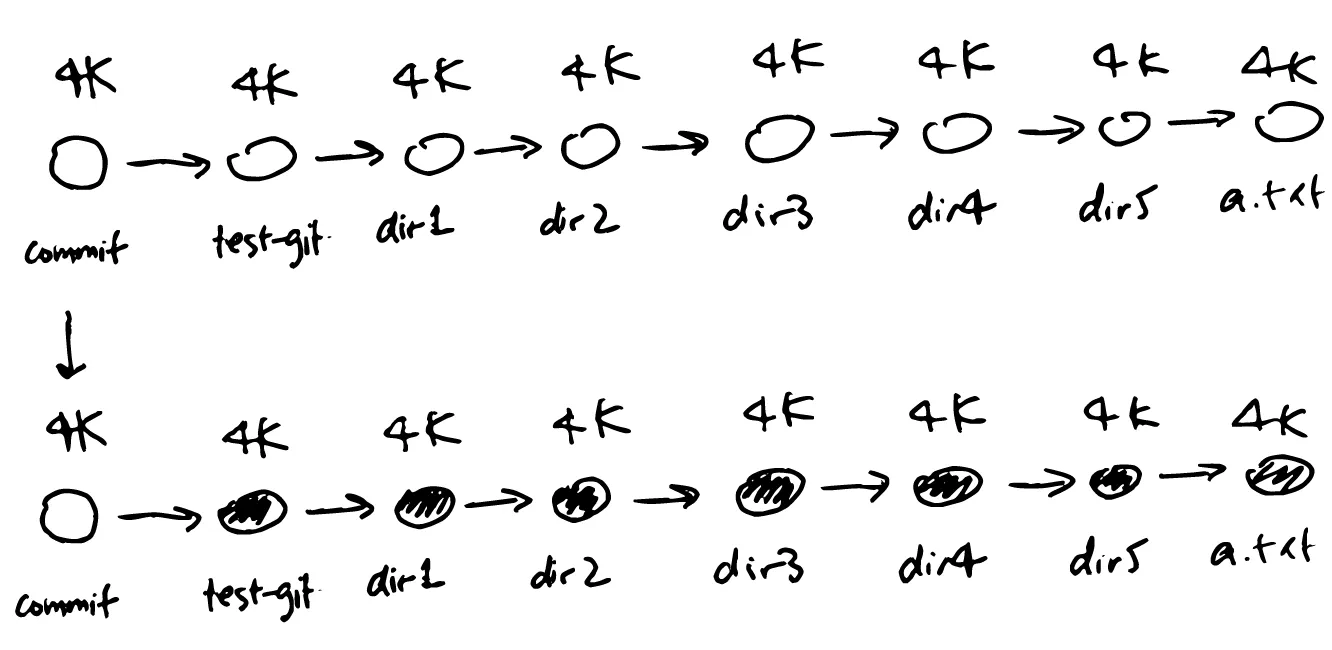
From what we know about subdirectory hashes changing, it makes sense, because in this case Git has to create new tree objects for the entire chain. In this case, it has to create 8 new objects, each 4K in size. To confirm, you can see the number of files increasing in .git/objects:
du -h .git/objects(rm -rf test-git to cleanup after you’re done!)
I’m fudging over some of the details here, but recall that the purpose of this post is just to give some intuition on how it works on a high level. I’ll suggest Chapter 10 of Pro Git for a deeper dive!