Like objects, closures are a mechanism for containing state. In JavaScript, a closure is created whenever a function accesses a variable defined outside the immediate function scope. It’s easy to create closures: Simply define a function inside another function, and expose the inner function, either by returning it, or passing it into another function. The variables used by the inner function will be available to it, even after the outer function has finished running.
Most online articles on closures start with a definition that resembles something like the above. It’s a description of its behaviour and how to create one. What most of them (read: all of them) fail to do is explain how closures are actually implemented, and then, why they behave the way they do. I believe this is important for truly understanding closures, and eventually, why closures are as important as they are.
This is a post on how closures are implemented in Ruby, and it is directly inspired from Pat Shaughnessy’s excellent book Ruby Under a Microscope. I also wrote 2 other posts as notes while going the book: How Ruby Classes Are Implemented and How Ruby Objects Are Implemented.
A closure is a data structure that contains a lambda expression, which is a function that takes a set of arguments, and an environment to be used when the lambda expression is invoked.
Closures in Ruby can be created in a few different ways. Here, a closure is created using a do block:
outside_string = "I am a string."
5.times do |n|
p "Iteration #{n}: #{outside_string}"
endWhen the first line is executed, Ruby first creates a RString structure representing the string I am a string. on the heap, and then pushes a reference to the RString onto its internal stack, in the current stack frame.
At the same time, the current rb_control_frame_ton the Ruby call stack also has a EP pointer (EP stands for Environment Pointer) referencing the current stack frame:
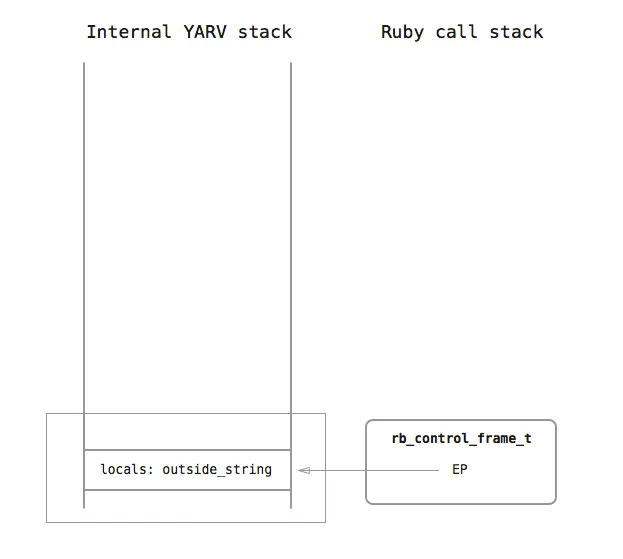
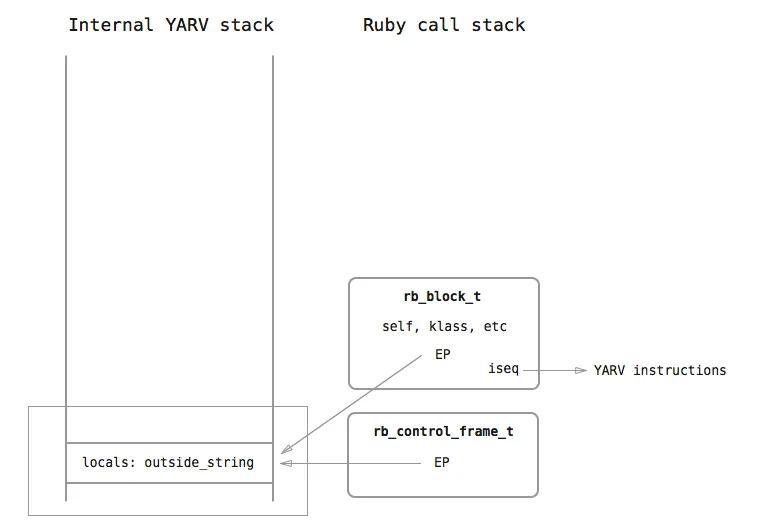
When the second line is executed, the Ruby tokenizer has already determined that a do block is present to be passed to the times method as an argument. YARV pushes a C structure representing the block, called rb_block_t, onto the call stack. rb_block_t contains a few things:
typedef struct rb_block_struct {
VALUE self;
VALUE klass;
VALUE *ep;
rb_iseq_t *iseq;
VALUE proc;
} rb_block_t;self is the value the self pointer in the block’s environment.
klass refers to the class of the current object.
*ep is identical to the EP pointer found in the preceding rb_control_frame_t, which references the current internal stack frame.
*iseq is a pointer to the compiled YARV instructions that correspond to the Ruby code inside the block, which in this case is:
p "Iteration #{n}: #{outside_string}"If we disassemble the line above, we can see the actual YARV instructions:
code = <<END
p "Iteration \#{n}: \#{outside_string}"
END
puts RubyVM::InstructionSequence.compile(code).disasm== disasm: <RubyVM::InstructionSequence:<compiled>@<compiled>>==========
...
0002 putself
0003 putobject "Iteration "
0005 putself
0006 opt_send_without_block <callinfo!mid:n, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0008 tostring
0009 putobject ": "
0011 putself
0012 opt_send_without_block <callinfo!mid:outside_string, argc:0, FCALL|VCALL|ARGS_SIMPLE>
0014 tostring
0015 concatstrings 4
0017 opt_send_without_block <callinfo!mid:p, argc:1, FCALL|ARGS_SIMPLE>
...
These are the actual instructions that YARV will execute when 5.times is run with the block as its argument. This is how the stacks look like when the block is evaluated.
Then, when 5.times is actually executed, Ruby creates another frame stack for the times method.
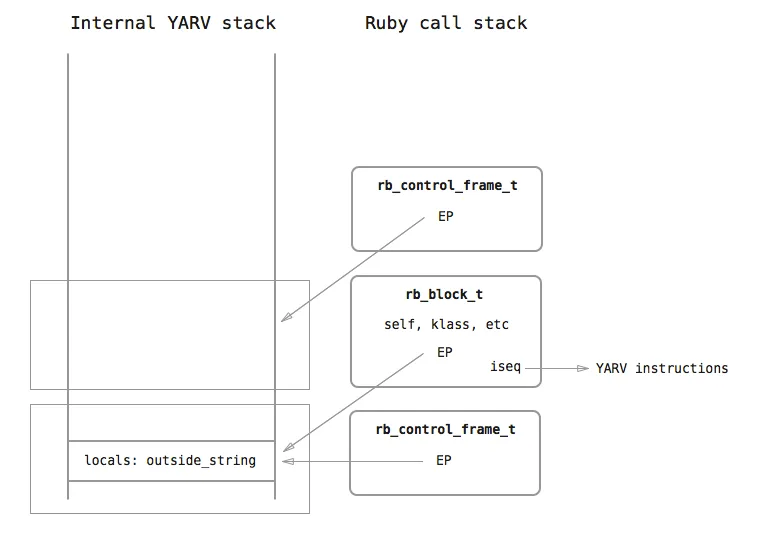
Within the times method, there is a call to yield that executes the block for each iteration, which means that there is yet another stack frame created for it:
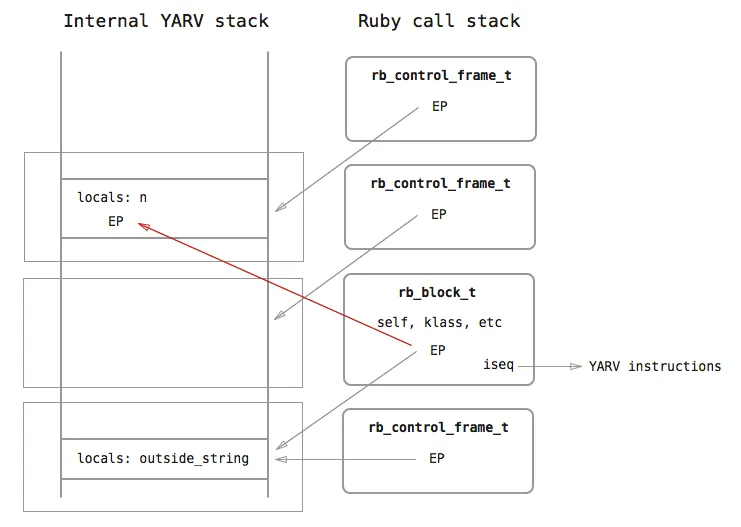
There are now three stack frames here. The bottom one belongs to the top-level scope (which could be the top-level Ruby scope, or a function), the middle one belongs to the times method, and the top one belongs to the currently executing block.
The yield method also does another crucial job: it copies the EP in the block’s rb_block_t to the block’s current stack frame. The copying is indicated with a red arrow in the diagram. This is what allows the block to access both its own local variables (like n) as well as the variables in the surrounding environment.
This is how a closure is achieved with a do block in Ruby - the block here is the lambda expression, and it is associated with an environment when it is called, using the EP that is copied by yield.
We now explore the other way of creating closures in Ruby: lambdas and procs. Lambdas and procs have a pattern that is quite similar to what one might see in JavaScript, for good reason: they are a representation of functions as a data value that can, amongst other things, be the return value of another function. For this discussion, we will look at this example:
def name_filler
private_string = "My name is:"
lambda do |name|
puts "#{private_string} #{name}"
end
end
x = name_filler
x.call('John') # "My name is: John"The equivalent version in JavaScript would look something like:
function nameFiller() {
const private_string = "My name is:";
return function (name) {
console.log(`${private_string} ${name}`);
};
}
let x = nameFiller();
x("John"); // "My name is: John"Recall that strings are created on the heap and referenced in the stack. When name_filler is executed during the assignment of the variable x, a RString representing My name is: is created on the heap and a single reference to it is pushed onto the stack. Then, when the name_filler function returns, its stack frame is popped off the stack, and there are no longer any references to that RString structure on the heap, which means that it is eligible for garbage collection.
However, when we call the method call on x in the next line, it still “knows” the value of private_string and returns what we expect: My name is: John.
What gives?
The reason lies in the lambda method. When lambda is called, what Ruby does is that it copies everything in the current stack frame into the heap.
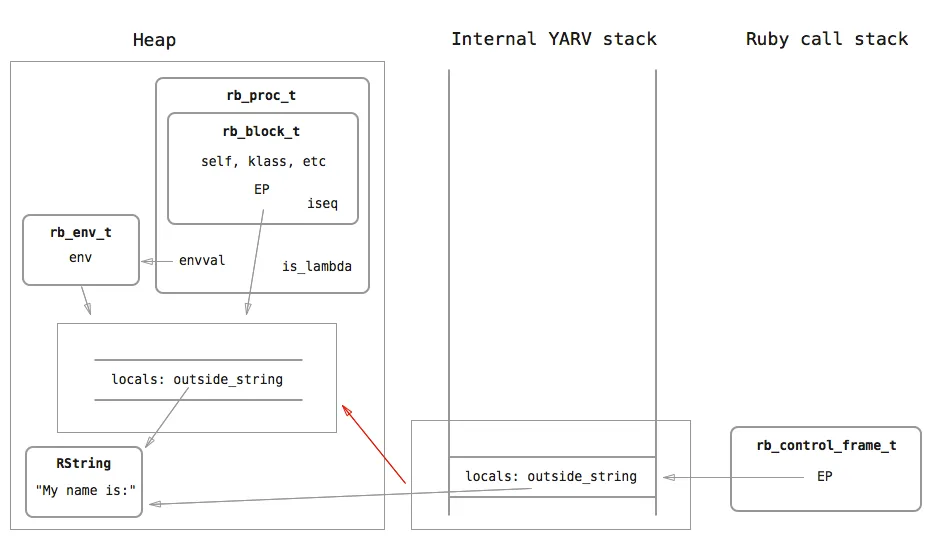
Along with the copy of the stack frame, Ruby also creates two other objects: rb_env_t, which acts as a wrapper around the copy of the stack frame, and rb_proc_t, which is the actual object that is returned from name_filler. rb_proc_t contains a rb_block_t structure whose EP references the heap copy of the stack frame, not the original stack frame on the stack. In this manner, you can think of rb_proc_t as a wrapper around rb_block_t that allows blocks to be represented as actual objects. rb_proc_t also has a is_lambda flag to indicate whether it was created as a proc using proc or Proc.new, or as a lambda using lambda. The differences between the two are relatively minor, and you can look them up.
Now, when name_filler is returned and its stack frame is popped off the stack, there is still a reference to the RString which originates from its clone in the heap, which is what allows x.call('John') to execute like how we’d expect. This is how the stack looks like after the name_filler stack frame is popped off. There is a variable x in the parent scope that now references the rb_proc_t:
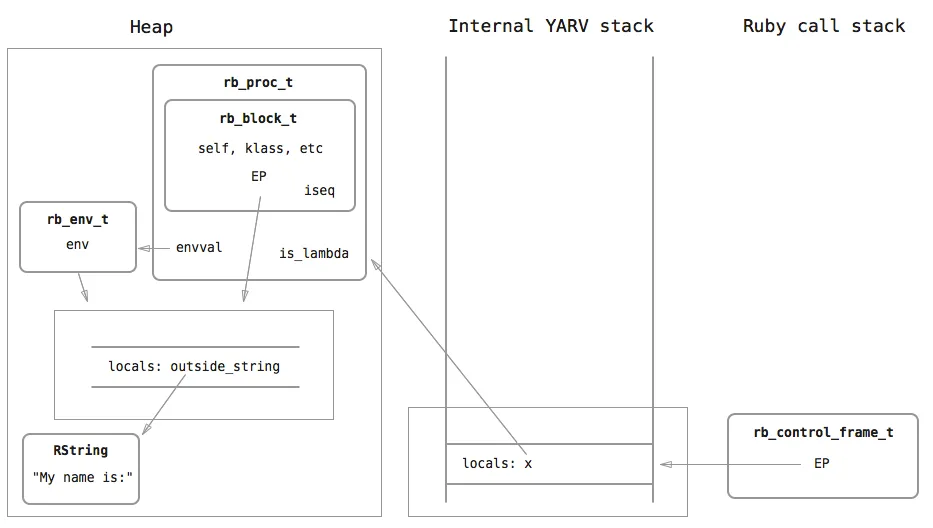
When the call method executes, a stack frame for the block is created on the stack, as usual. Instead of yield copying the EP reference from the relevant rb_block_t in the case of blocks, we now get it from the rb_proc_t instead:
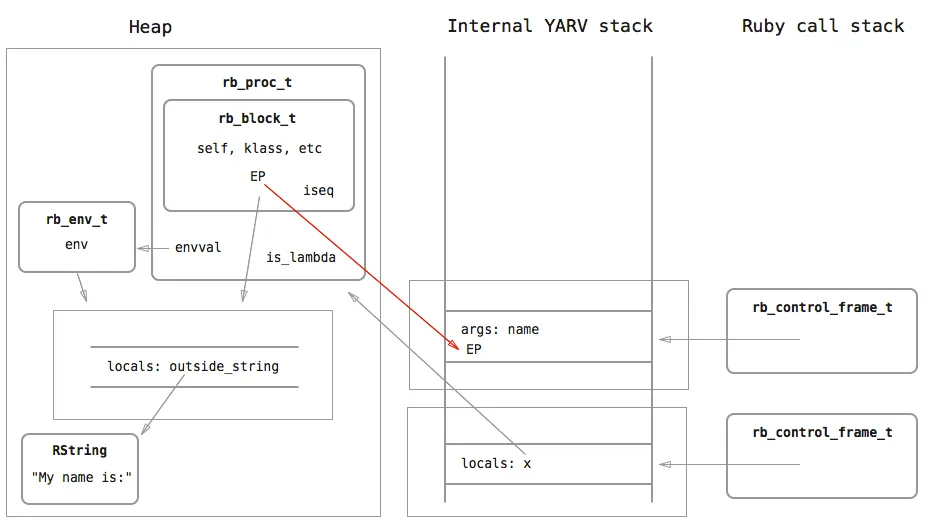
This is how a closure is created with lambdas and procs in Ruby. As you can see, the representing structure, rb_proc_t, fulfils the two properties of closures: it contains a lambda expression, as well as a reference to an environment that it was created in. rb_proc_t, being an object on the heap, is able to persist across function calls and can be passed around as a value, whereas blocks, being represented by rb_block_t on the stack, are lost as soon as the current stack frame is popped off, and cannot be passed around as a value.
#Conclusion
It’s quite likely that the implementation of closures in JavaScript (and other langauges) follows largely the same implementation principles of saving a copy of the current stack frame into the heap, so understanding this will lead to a language-agnostic understanding of the concept of closures.
Once I understood how closures were implemented, I was in awe of how elegant it was. I hope I manage to convey that same sense of awe in this post, and give you a clearer picture of what closures actually are, instead of describing in a circular manner their usage and behaviour.
Further reading: Closures in Ruby by Paul Cantrell (he seems to have a stricter definition of closures, but the general idea remains the same)