I recently wrote Topick, a library for extracting keywords from HTML documents.
The initial use case for it was to be used as part of a Telegram bot which would archive shared links by allowing the user to tag the link with keywords and phrases:
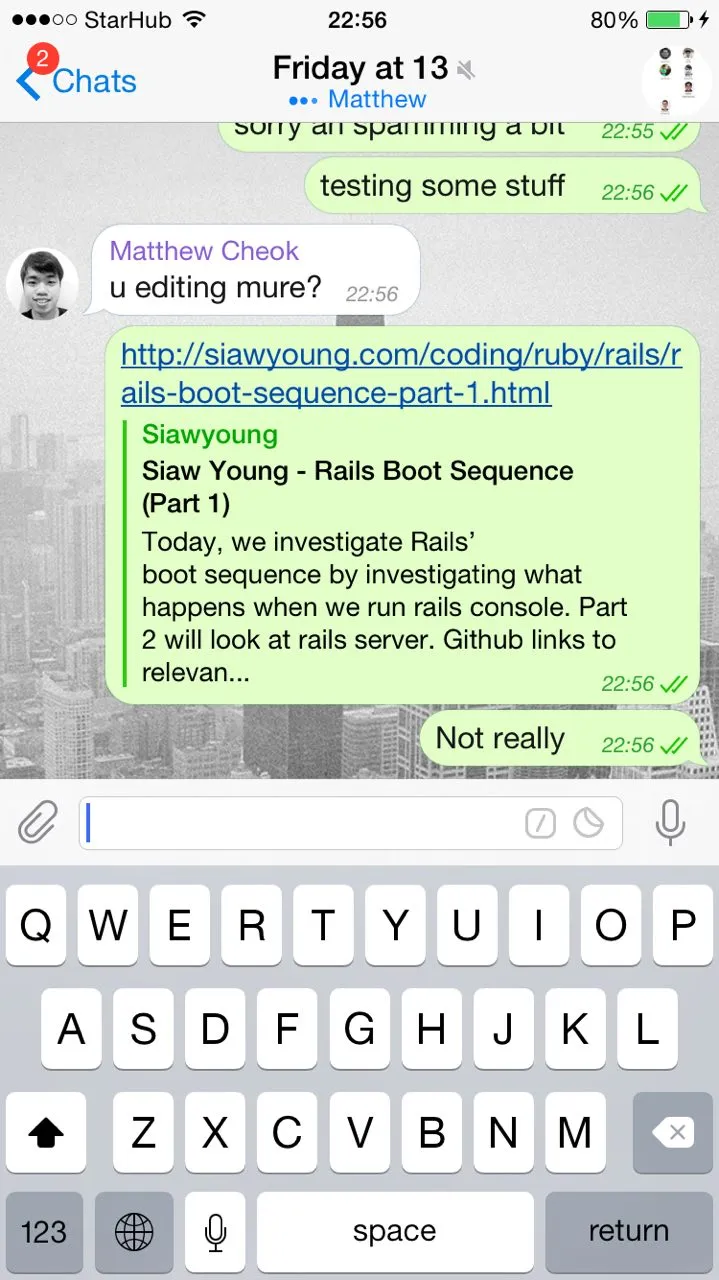
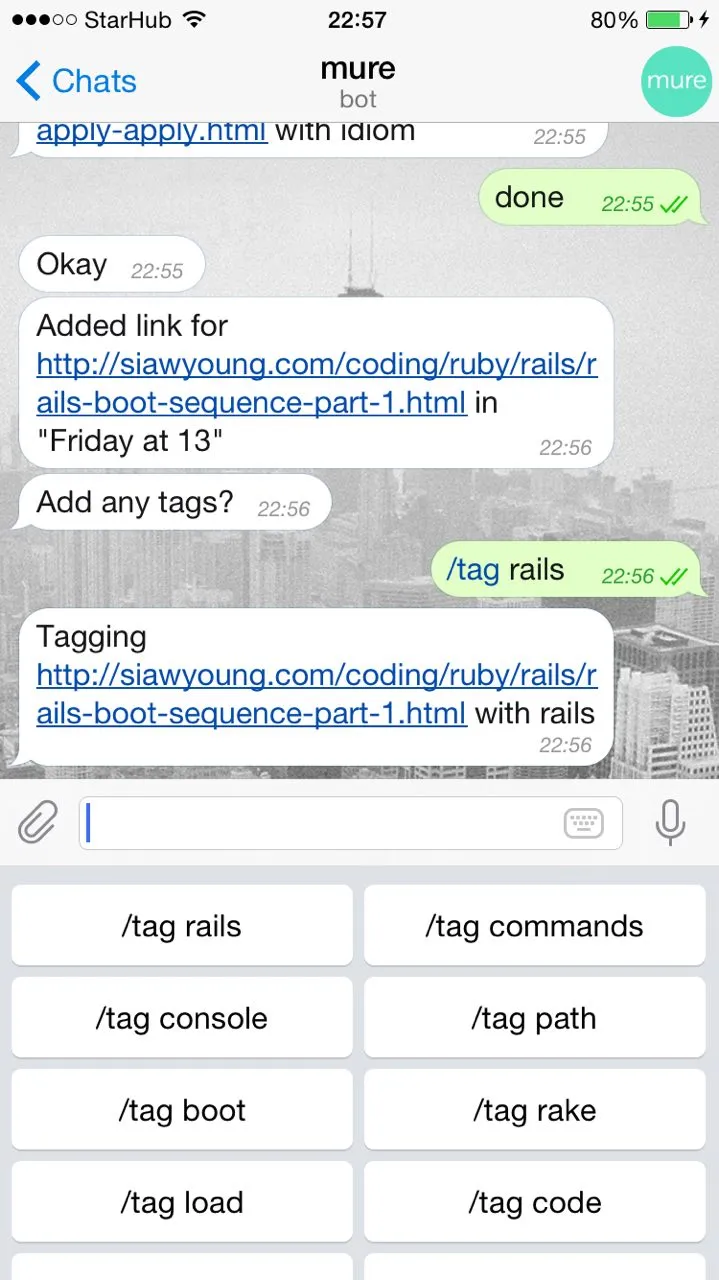
This blog post details how it works.
HTML parsing
Topick uses htmlparser2 for HTML parsing. By default, Topick will pick out content from p, b, em, and title tags, and concatenate them into a single document.
Cleaning
That document is then sent for cleaning, using a few utility functions from the textminer library to:
- Expand contractions (e.g. from I’ll to I will)
- Remove interpunctuation (e.g. ? and !)
- Remove excess whitespace between words
- Remove stop words using the default stop word dictionary
- Remove stop words specified by the user
Stop words are common words that are unlikely to be classified as keywords. The stop word dictionary used by Topick is a set union of all six English collections found here.
Generating keywords
Finally, the cleaned document can be used as input for generating keywords. Topick includes three methods of doing so, which all relies on different combinations of nlp-compromise library functions to generate the final output:
n-gramsnamedentitiescombined
The n-grams method relies solely on the generateNGrams method to generate keywords/phrases based on frequency. The generated words or phrases are then sorted by frequency and filtered (those with frequency 1 are discarded).
The namedentities method relies on the generateNamedEntitiesString method to guess keywords or phrases that are capitalized/don’t belong in the English language/are unique phrases. There’s also a frequency-based criterion here.
The combined method combines both by running both n-grams and namedentities and merging their output together before sorting them and filtering them. This method is the slowest but generally produces the best and most consistent output.
Custom options
Topick includes a few options for the user to customize.
ngram
{ min_count: 3, max_size: 1 }
The ngram method defines options for n-gram generation.
min_count is the minimum number of times a particular n-gram should appear in the document before being considered. There should be no need to change this number.
max_size is the maximum size of n-grams that should be generated (defaults to generating unigrams).
progressiveGeneration
This options defaults to true.
If set to true, progressiveGeneration will progressively generate n-grams with weaker settings until the specified number of keywords set in maxNumberOfKeywords is hit.
For example: if for a min_count of 3 and maxNumberOfKeywords of 10, Topick only generates 5 keywords initially, then progressiveGeneration will decrease the min_count to 2, and then to 1, until 10 keywords can be generated.
progressiveGeneration does not guarantee that maxNumberOfKeywords keywords will be generated (like if even at min_count of 1, your specified maxNumberOfKeywords still cannot be reached).